Bing 首页图片合集抓取
微软 Bing 首页以每日更新高质量壁纸而闻名,很多人喜欢下载作为桌面壁纸,本文介绍一种抓取 Bing 首页图片合集的思路。
抓取来源
- 首页单张图片: https://www.bing.com
- 官方首页图片合集:
http://www.bing.com/gallery/(已失效)
分析思路
由于本文需要抓取所有 Bing 首页图片的合集,所以选择 http://www.bing.com/gallery/(已失效) 作为抓取来源。
用 Chrome 浏览器打开该网址,页面布局如图:
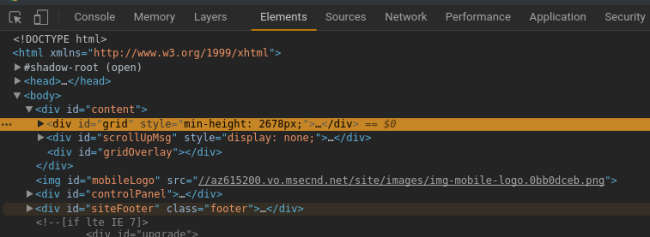
 身为程序员,习惯性 F12 检查下页面元素,我发现所有图片都在
身为程序员,习惯性 F12 检查下页面元素,我发现所有图片都在 id="gird" 的 div 块中,页面结构如图:
 按下 Ctrl + Shift + C 点击列表中一张图片,HTML 代码如图:
按下 Ctrl + Shift + C 点击列表中一张图片,HTML 代码如图:
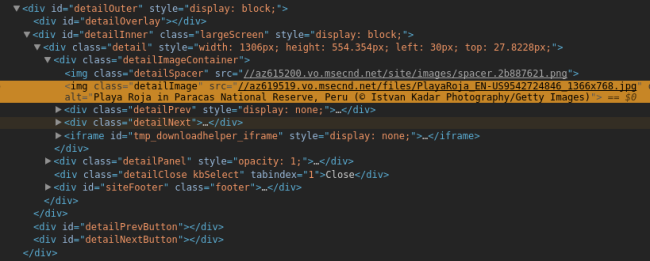
 点击图片查看详情,按下 Ctrl + Shift + C 点击大图,HTML 代码如图:
点击图片查看详情,按下 Ctrl + Shift + C 点击大图,HTML 代码如图:
 由此大胆猜测,图片 url 结构为: http(s)://az619519.vo.msecnd.net/files/{img_name}_{resolution}.jpg
由此大胆猜测,图片 url 结构为: http(s)://az619519.vo.msecnd.net/files/{img_name}_{resolution}.jpg
只要获得 {img_name} 就可以抓取对应的图片了。
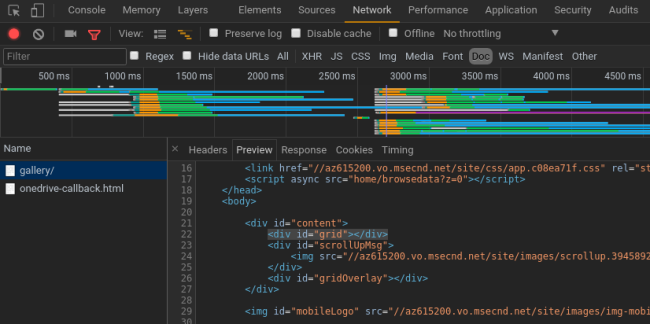
打开 Network -> Doc 菜单,最开始 id="gird" 的 div 块并没有数据,说明是通过 js 请求数据并渲染出来的:
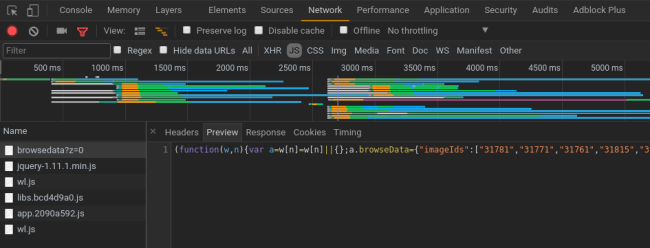
 打开 Network -> JS 菜单,果然看到我想要的数据:
打开 Network -> JS 菜单,果然看到我想要的数据:
 数据是在 js 代码中,可以通过正则表达式提取出来,再转成 json 格式,数据结构如下:
数据是在 js 代码中,可以通过正则表达式提取出来,再转成 json 格式,数据结构如下:
{
"imageIds": ["31781", "31771", "31761", ...],
"categories": ["Nature", "Nature", "Animal", ...],
"tags": ["Beach", "Plant / tree", "Mammal", ...],
"holidays": ["", "", "Father's Day", ...],
"regions": ["South America,", "", "", ...],
"countries": ["Peru", "", "", ...],
"colors": ["Multi", "Multi", "Brown", ...],
"shortNames": ["PlayaRoja", "AeoniumLeaf", "TurDad", ...],
"imageNames": ["PlayaRoja_EN-US9542724846", "AeoniumLeaf_EN-US7200082197", "TurDad_EN-US11284438848", ...],
"dates": [20170620, 20170619, 20170618, ...]
}imageNames 正好对应图片 url 中的 {img_name}。至此,就可以很轻松构造图片的 url。
以第一张图为例,根据猜测的图片 url 构成规则,对应的图片 url 为:
http(s)://az619519.vo.msecnd.net/files/PlayaRoja_EN-US9542724846_1366x768.jpg
打开链接,就是第一张分辨率为 1366x768 的图片,说明刚才猜测的图片 url 构成规则是正确的。

Python 代码
- bing_gallery_crawler.py
# -*- coding: utf-8 -*-
import json
import re
import requests
import shutil
data_url = 'http://www.bing.com/gallery/home/browsedata?z=0'
# img_detail_base_url = 'http://www.bing.com/gallery/home/imagedetails/%s?z=0'
regex = r'a\.browseData=(.+);}\)\(window, \'BingGallery\'\);'
img_base_url = 'https://az619519.vo.msecnd.net/files/%s_%s.jpg'
resolution = '1366x768'
gallery_data_js = requests.get(data_url)
gallery_data_match = re.search(regex, gallery_data_js.content)
if gallery_data_match:
gallery_data_json = json.loads(gallery_data_match.group(1))
img_ids = gallery_data_json['imageIds']
img_names = gallery_data_json['imageNames']
short_names = gallery_data_json['shortNames']
for index in xrange(len(img_ids)):
# img_detail_url = img_detail_base_url % img_ids[index]
img_url = img_base_url % (img_names[index], resolution)
file_name = short_names[index] + '.jpg'
img_stream = requests.get(img_url, stream=True)
if img_stream.status_code == 200:
with open(file_name, 'wb') as fw:
shutil.copyfileobj(img_stream.raw, fw)
else:
print "No match!"- GitHub 源代码地址: https://github.com/benheart/BingGallery
参考链接
- Bing 图片下载 - 知乎: https://www.zhihu.com/question/20583304
